近日,上海财经大学统计与数据科学学院,上海财经大学数量金融与风险管理研究中心张立文副教授领导的金融大语言模型课题组,在我校实验中心超算平台的支持下,联合金融学院,城乡发展研究院正式发布了金融领域大语言模型测评数据集FinEval,并提供了详细的论文、Github以及评测文档。该课题组由六位博士和多位硕士组成,组内成员研究方向包括统计理论、大数据与人工智能分析、深度学习、量化投资和大模型等,具有统计、大数据、人工智能、计算机以及金融等复合背景。FinEval评估基准旨在评估大语言模型(LLM)在中国背景下对金融领域通用知识的理解、金融数学计算和推理能力。
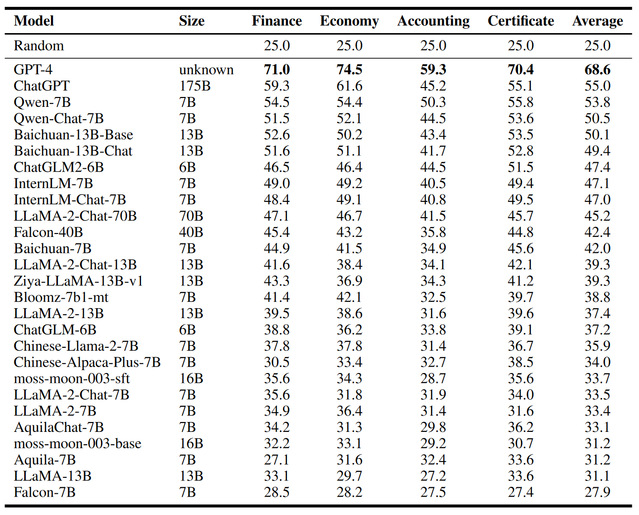
该基准测评数据集包含4661道选择题,涉及金融(Finance)、经济(Economy)、会计(Accounting)和金融类考证(Certificate)等四个主要类别,涵盖34个不同科目,具体结果见图1。为确保评估的准确性和全面性,课题组选取目前主流的GPT-4,Qwen, BaiChuan,ChatGLM2,LLaMA2,InternLM等二十多个国内外大语言模型进行广泛评测。

图1:FinEval数据集,包括金融,经济,会计及各类金融类考证
与以往的评测基准相比,FinEval有以下优点:(1)专注于金融领域的综合知识,涵盖不同难度的题目。(2)大部分数据来自于难以在线抓取的模拟考试,题目获取难度大,真实度高,金融类考证题目主要基于这种方法获取。(3)覆盖现在大部分知名的开源与闭源的27个模型,这种综合的选择涵盖了不同的语言、规模和任务,确保了评估的全面性。根据FinEval评估结果显示,27个参与评估的模型中,GPT-4表现最为出色,在所有类别中的平均准确率接近70%。ChatGPT紧随其后,与GPT-4相比,仅有13.6个百分点的差距。Qwen-7B和Qwen-Chat-7B分列第三和第四,准确率分别达到53.8%和50.5%,具体结果见表1。
表1:FinEval金融大模型评测得分排行榜
FinEval通过整合金融、经济、会计和金融类考证等领域的高质量国内数据,使其全面性和准确性更为突出。目前,FinEval测评集数据主要集中于金融领域的通用知识,未来将陆续推出金融虚拟助理和围绕金融犯罪检测、欺诈评估等的应用场景,以及包含金融安全规范、金融伦理道德的评估基准。
总而言之,FinEval的出现填补了目前中国金融领域评估基准的空白,对于进一步探索金融任务中语言模型的评估方法具有重要意义。课题组的这一研究成果值得再次表示热烈祝贺!我们衷心期待课题组能够继续推出更多大语言模型方面的创新成果,为金融领域注入新动力。
FinEval评估基准目前已正式发布,欢迎对大模型感兴趣的同学以及在数据、算力、金融等方面的学界或业界合作伙伴与张立文副教授联系。后续课题组将继续推出更多科研成果。
FinEval评估项目GitHub地址:https://github.com/SUFE-AIFLM-Lab/FinEval
论文地址:https://arxiv.org/abs/2308.09975
评测文档:https://fineval.readthedocs.io
联系邮箱:zhang.liwen@shufe.edu.cn
